к МР 1.2.0344-24
5.1. Данные, полученные при обработке файлов РП, преобразуют в таблицу формата ".csv" для каждой пробы в отдельности, содержащую результаты анализа как в положительном, так и в отрицательном режимах ионизации, со следующими наименованиями колонок:
- "mz" - массово-зарядовое число квазимолекулярного иона вещества;
- "rt" - время удерживания соответствующего вещества, мин;
- "into" - площадь аналитического сигнала.
Для каждой экспериментальной группы создают папку, в которую размещают результаты анализа РП. Из папок, содержащих сгруппированные файлы, формируют архив формата ".zip". Для корректной обработки в программном обеспечении, наименования всех файлов, папок и общего архива не должны содержать символы кириллицы.
5.2. Данные загружают в разделе "Статистический анализ" (англ. Statistical analysis), расположенном в окне обзора модулей анализа (англ. Module overview) (рис. П5.1 и П5.2).

Рис. П5.1 - интерфейс программного обеспечения
"MetaboAnalyst"

Рис. П5.2 - окно выбора метода анализа
5.3. В окне выбора формата данных, в разделе "Сжатый файл" (англ. A compressed file), посредством нажатия кнопки "Выбрать" (англ. Choose) выбирают и загружают архив с файлами эксперимента, далее выбирают тип данных "Список масс-спектрометрических пиков" (англ. MS peak list) и подтверждают операцию нажатием на кнопку "Подтвердить" (англ. Submit) (рис. П5.3).

Рис. П5.3 - окно выбора формата данных
5.4. В появившемся окне задают точность определения времени удержания в секундах и m/z. После подтверждения параметров выравнивания, система отобразит информацию о количестве загруженных файлов (англ. Data integrity check), содержащих результаты анализа проб аналитических сигналов веществ, о количестве экспериментальных групп и пропущенных значениях (рис. П5.4).

Рис. П5.4 - окно, содержащее информацию о загруженных данных
5.5. Для выполнения импутации пропущенных значений переходят во вкладку "Пропущенные значения" (англ. Missing Values). Данный процесс в результатах анализа проб проводят посредством присвоения значения сигнала, соответствующего теоретическому пределу обнаружения вещества. Из обработки исключают вещества, имеющие более половины пропущенных значений аналитического сигнала среди всех проб (рис. П5.5).
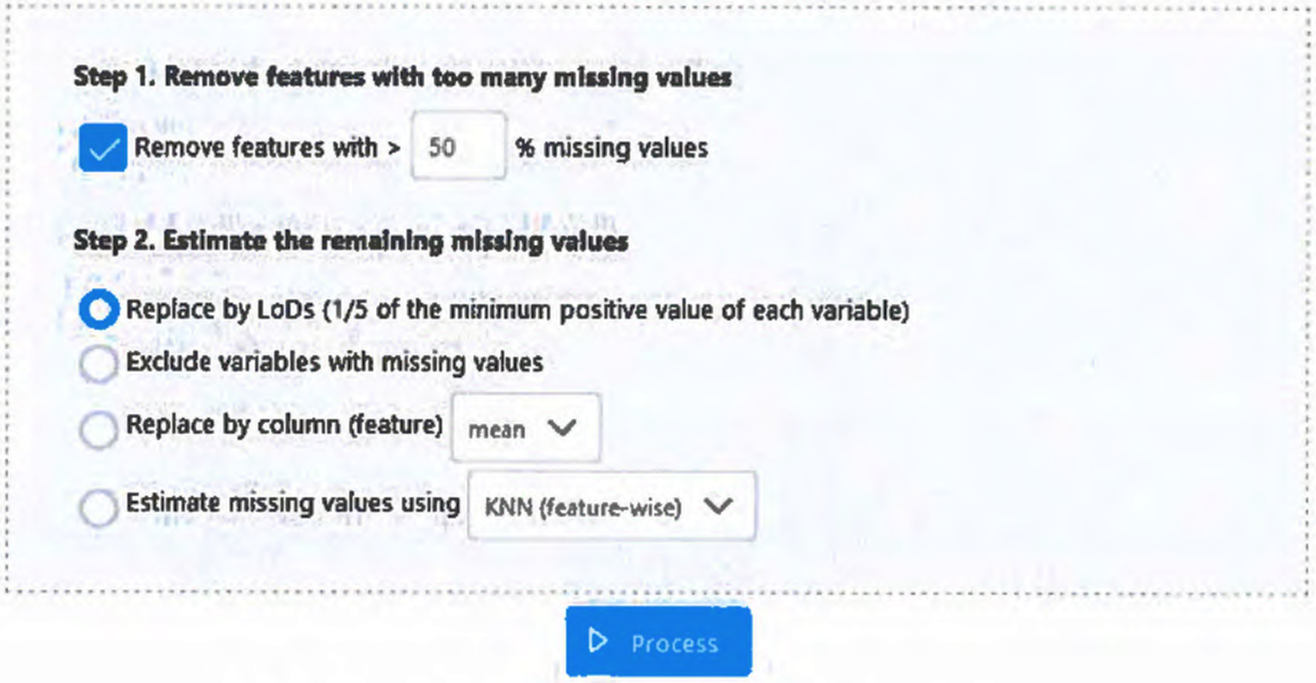
Рис. П5.5 - окно выбора параметров импутации
5.6. Удаление неинформативных значений аналитических сигналов проводят посредством оценки стандартного отклонения или межквартильного размаха величины сигнала фильтры "Стандартное отклонение" (англ. Standard deviation) и "Межквартильный размах" (англ. Interquartile range), соответственно, и по среднему или медиане значений сигнала фильтры "Среднее значение интенсивности" (англ. Mean intensity value) и "Медианное значение интенсивности" (англ. Median intensity value), соответственно (рис. П5.6). В окне "Статистические фильтры" (англ. Statistical filters) необходимо выбрать соответствующий фильтр, и применить его нажатием кнопки "Подтвердить" (англ. Submit) после каждого выбранного фильтра, т.к. их действие является аддитивным. По окончании отбора данных переходят к этапу нормализации нажатием кнопки "Продолжить" (англ. Proceed).

Рис. П5.6 - окно выбора параметров отбора данных
5.7. Нормализация сигналов веществ в РП проводят с использованием вещества-стандарта. Для этого в окне "Нормализация проб" (англ. Sample normalization) выбирают пункт "Нормализация по референсному сигналу" (англ. Normalisation by reference feature) и в выпадающем списке отмечают сигнал, соответствующий ВС (рис. П5.7).

Рис. П5.7 - окно выбора параметров нормализации данных
5.8. В окне "Статистические методы" (англ. Statistics) представлены методы получения информации о сигналах, величины которых значимо отличаются в экспериментальных группах (рис. П5.8).

Рис. П5.8 - окно выбора методов статистического анализа
5.9. Классический статистический анализ представлен в виде "вулканообразной" диаграммы (англ. Volcano plot, далее - Volcano plot), учитывающим статистическую значимость отличий с поправкой на множественные сравнения или без (пункты "Коррекция с учетом оценкой ложноположительных результатов" (англ. false discovery rate, FDR) и "Данные без обработки" (англ. Raw), соответственно) и кратность изменения сигнала (англ. Fold change) (рис. П5.9). Пороговые значения данных параметров задают в соответствующих полях. По умолчанию, для проведения межгрупповых сравнений используется t-критерий Стьюдента (использование U-критерия Манна-Уитни выбирают отметкой пункта "Непараметрический критерий" (англ. Non-parametric tests). Результат анализа выгружают в виде изображения или таблицы формата Excel, содержащей m/z выбранных веществ, время удержания, p-значение и кратность изменения сигнала (рис. П5.10).

Рис. П5.9 - параметры статистического анализа

Рис. П5.10 - пример статистической обработки данных
с построением Volcano plot: по вертикальной оси отложено
значение отрицательного логарифма значения p (пороговое
значение отмечено горизонтальной пунктирной линией),
по горизонтальной - кратность изменения сигнала;
вещества, отмеченные серыми точками, не показали
значимого изменения сигнала, синими - показали
статистически значимое уменьшение, красными - увеличение
сигнала в направлении сравнения
5.10. Многомерный статистический анализ данных результатов измерений РП выполняют методами главных компонент, который проецирует значения сигналов всех веществ от всех проб на двухкоординатную плоскость, уменьшая таким образом размерность данных и демонстрируя тенденцию в изменении сигналов между двумя экспериментальными группами и их выбросы (рис. П5.11).

Рис. П5.11 - пример результата обработки
данных методом главных компонент. Расхождение областей
(красный и зеленый эллипсы), относящихся к пробам
из различных экспериментальных групп, свидетельствует
об отличиях между ними
5.11. Метод PLS-DA позволяет с определенной достоверностью установить вещества, сигналы которых привели к наибольшим межгрупповым различиям (рис. П5.12). При удовлетворительных значениях Q2-критерия и p-значения для интерпретации метаболомного эксперимента используют вещества, представленные на вкладке "Значимые вещества" (англ. Important features), отсортированные по величине значимости изменений сигналов в проекции на компоненты регрессионной модели или коэффициенту регрессии. Данные выгружают в виде таблицы, содержащей m/z и время удерживания вещества, значения проекций на компоненты или суммарные коэффициенты регрессии.

Рис. П5.12 - пример результата обработки данных методом
частично-наименьших квадратов
- Гражданский кодекс (ГК РФ)
- Жилищный кодекс (ЖК РФ)
- Налоговый кодекс (НК РФ)
- Трудовой кодекс (ТК РФ)
- Уголовный кодекс (УК РФ)
- Бюджетный кодекс (БК РФ)
- Арбитражный процессуальный кодекс
- Конституция РФ
- Земельный кодекс (ЗК РФ)
- Лесной кодекс (ЛК РФ)
- Семейный кодекс (СК РФ)
- Уголовно-исполнительный кодекс
- Уголовно-процессуальный кодекс
- Производственный календарь на 2025 год
- МРОТ 2026
- ФЗ «О банкротстве»
- О защите прав потребителей (ЗОЗПП)
- Об исполнительном производстве
- О персональных данных
- О налогах на имущество физических лиц
- О средствах массовой информации
- Производственный календарь на 2026 год
- Федеральный закон "О полиции" N 3-ФЗ
- Расходы организации ПБУ 10/99
- Минимальный размер оплаты труда (МРОТ)
- Календарь бухгалтера на 2026 год
- Частичная мобилизация: обзор новостей
- Постановление Правительства РФ N 1875